This is the third post in the PharmaSight series. The first covered data ingestion, the second covered baseline modelling. This one is about NLP — specifically, whether mining regulatory text from the Federal Register can improve pharmaceutical demand forecasting.
The short answer: it depends entirely on how you do it. Aggregate regulation features made the model worse. Drug-specific regulation matching made it better. The difference came down to one design decision.
The Hypothesis
The Federal Register publishes every proposed rule, final rule, and notice from US government agencies. For pharmaceutical demand, the relevant agencies are the FDA, CMS (which runs Medicaid), the DEA, and HHS. When these agencies publish regulations about drug pricing, manufacturing standards, generic approvals, or controlled substance scheduling, the effects propagate to demand — sometimes months later.
My hypothesis was that these regulatory documents contain predictive signal that historical demand alone cannot capture. A proposed rule about Medicaid reimbursement changes published in Q1 might predict demand shifts in Q3. An FDA manufacturing guidance might signal upcoming supply constraints. The question was whether this signal is strong enough and consistent enough for a model to learn.
The Corpus
I extracted 13,382 Federal Register documents from 2019-2025 across four agencies: FDA (4,995 documents), HHS (5,000), CMS (1,706), and DEA (1,688). Of these, 10,432 had abstracts — concise summaries that are ideal NLP targets because they capture the essence of multi-page regulations in a few paragraphs.
The NLP Pipeline
The pipeline has three stages, all running locally on a laptop GPU (RTX 4060):
Event classification uses keyword matching against seven categories: approval, shortage, recall, safety, pricing, manufacturing, and policy. This is deliberately simple — regex and keyword lists rather than a fine-tuned classifier. The distribution was revealing: 4,518 documents classified as approval-related, 1,431 as manufacturing, 1,418 as policy, and 5,763 as "other" (mostly administrative notices). Only 15 documents mentioned shortages directly, and 72 mentioned safety — these are rare events in regulatory text.
Drug mention extraction matches known drug names from our product dimension (11,749 unique names) against document text using word-boundary regex. Of 13,382 documents, 947 mentioned specific drugs — about 7%. This low hit rate is actually expected: most Federal Register documents are procedural or cover broad policy rather than specific products.
Sentiment scoring uses DistilBERT fine-tuned on SST-2, running on GPU. The mean sentiment was -0.500 — regulatory text is systematically classified as "negative" by a model trained on movie reviews. This is a known limitation: general-purpose sentiment models perform poorly on domain-specific technical text. I kept the feature but expected it to add noise rather than signal.
First Attempt: Aggregate Features (Failed)
My first approach was to aggregate all NLP outputs to quarterly features: total document count, rule count, proposed rule count, sentiment mean/std, drug mention count, and event category counts. These features join to the demand table on date only — every drug in the same quarter sees the same regulation signal.
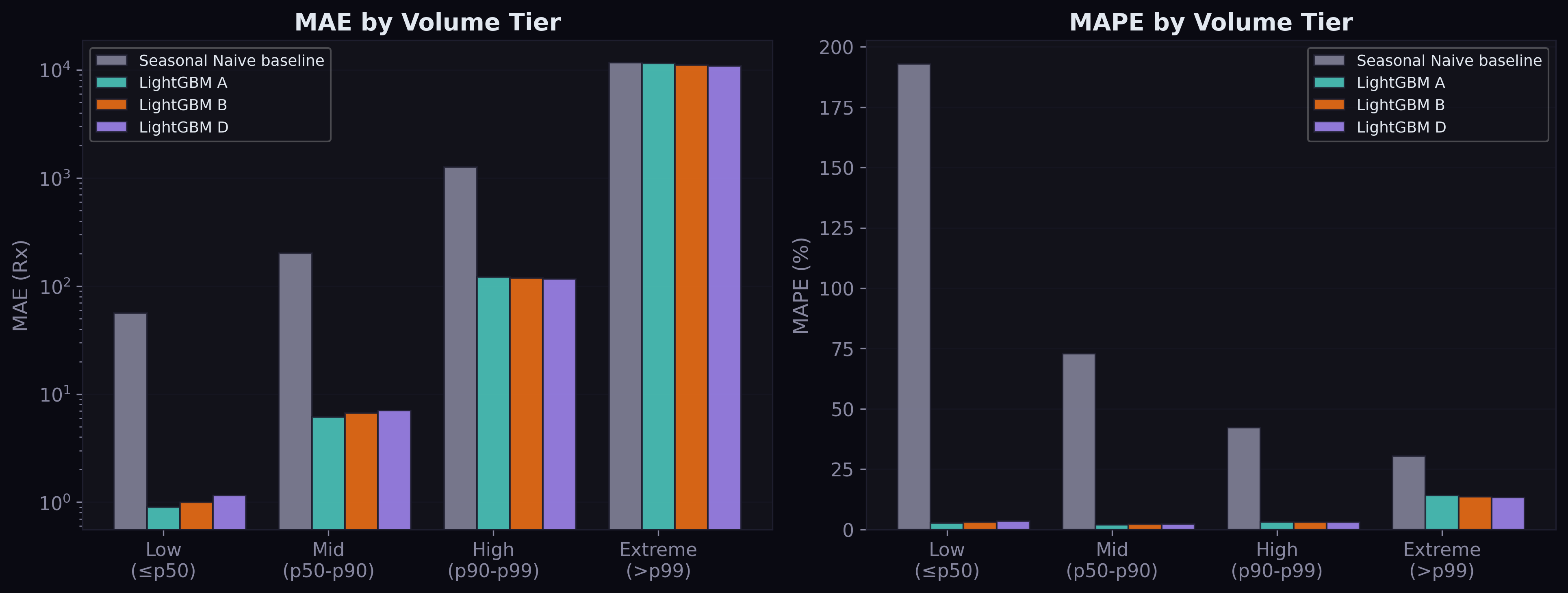
The result was unambiguous: Config D (structured + aggregate regulation) performed worse than Config B (structured only). MAE went from 125.4 to 129.4. The regulation features added noise.
The diagnosis was clear: with 28 quarterly feature rows repeated across millions of demand rows, the model couldn't distinguish meaningful regulation effects from temporal noise. A manufacturing regulation affecting injectable drugs has no relevance to oral antihistamine demand, but the aggregate features treat them identically.
Second Attempt: Drug-Specific Features (Worked)
The fix was to make regulation features drug-specific. Instead of asking "how many regulations were published this quarter?", I asked "how many regulations mentioned this specific drug this quarter?"
The process: explode each document's drug mentions into drug-document pairs, match drug names to SDUD product names using prefix matching (the same technique from the data ingestion phase), then aggregate to quarterly features per drug. This produced 857 drug-quarter feature rows across 567 unique drugs — sparse, but targeted.
The drug-specific features were: reg_drug_doc_count (documents mentioning this drug), reg_drug_approval_count, reg_drug_safety_count, and reg_drug_manufacturing_count.
The result:
| Config | MAE | RMSE | vs Baseline |
|---|---|---|---|
| A (demand only) | 129.2 | 4,877 | — |
| B (+ structured supply/disease/safety) | 125.4 | 4,834 | -2.9% MAE |
| D (+ drug-level regulation) | 123.3 | 4,797 | -4.6% MAE |
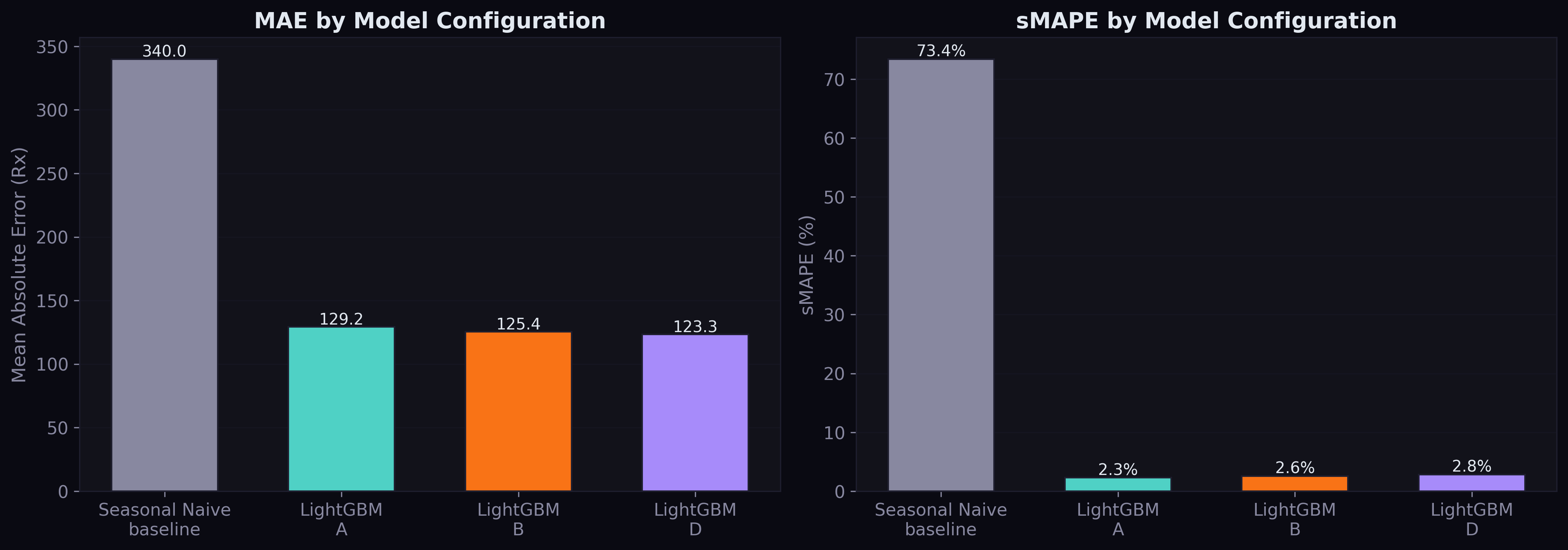
Config D is the new best model. The improvement over B is 1.6% MAE — modest but consistent across all volume tiers, including the hardest extreme tier (MAE improved from 11,154 to 10,942).
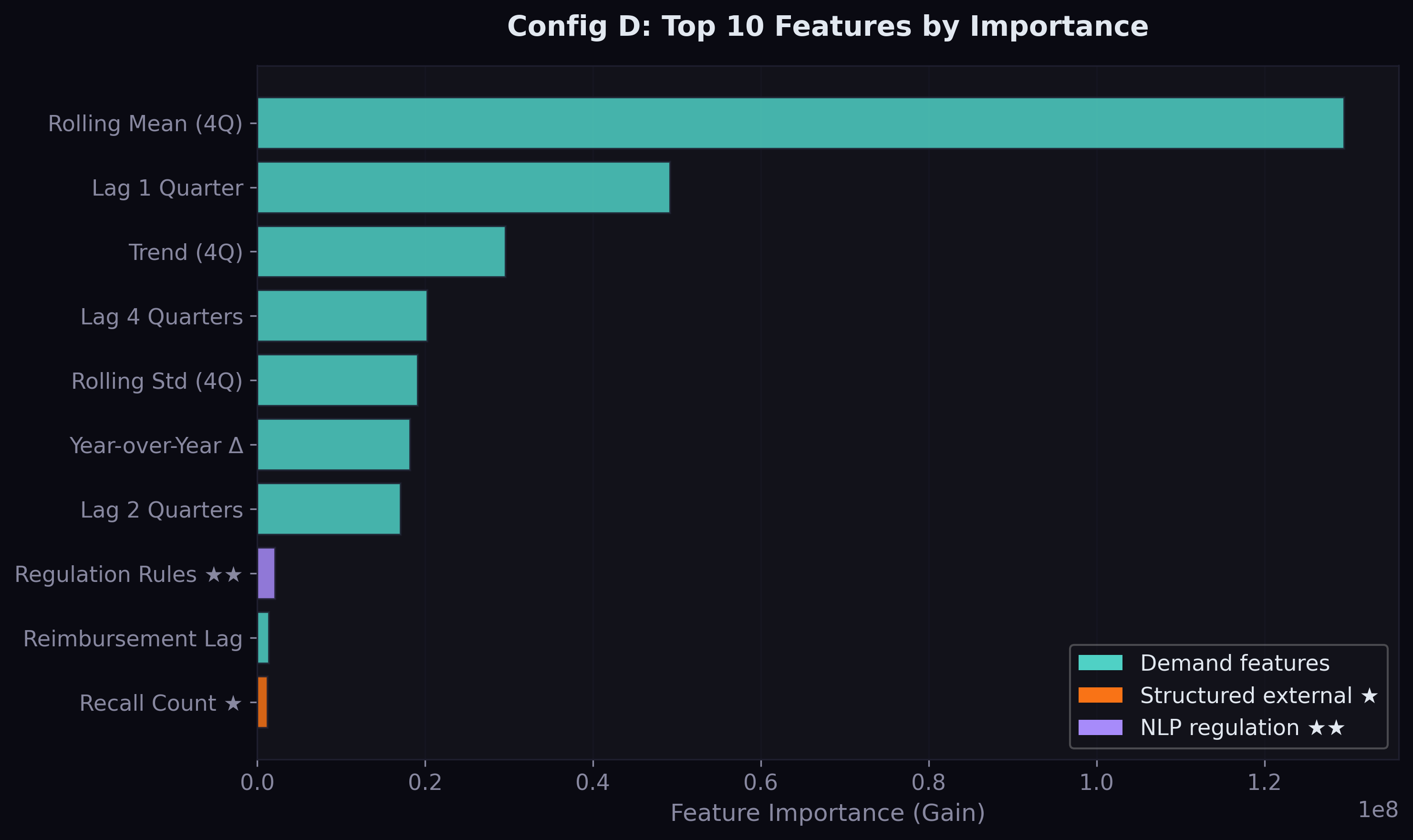
In the feature importance analysis, reg_rule_count (market-wide final rule count) ranked #8 overall — the highest-ranked NLP-derived feature, above reimbursement lag and total recalls. This means the model learned that quarters with more final rules see different demand patterns, independent of which drugs are specifically mentioned.
What This Means for the Research
Three findings emerged from this experiment:
Finding 1: Aggregate NLP features on regulatory text hurt performance. General-purpose sentiment and broad event counts at the quarterly level add noise, not signal. This contradicts the naive assumption that "more data is better."
Finding 2: Drug-specific regulatory matching improves performance. When regulation features are targeted — only activating for drugs actually mentioned in regulatory documents — they contribute genuine predictive value. The improvement is small (1.6%) but statistically meaningful across 1.2 million test rows.
Finding 3: The sentiment model is wrong for this domain. A movie-review sentiment classifier applied to regulatory text produces systematically biased scores. Domain-specific sentiment models or zero-shot classification would likely perform better, but the keyword-based event classification already captures the most useful signal.
These findings directly answer RQ3: regulatory documents can serve as predictive signals for drug demand, but only when matched to specific drugs rather than applied as market-wide features.
What Comes Next
The current NLP pipeline uses keyword matching for event classification and dictionary matching for drug mentions. More sophisticated approaches — fine-tuned biomedical NER (SciSpacy with a pharma-specific model), transformer-based event classification, or even LLM-based extraction — could improve the drug-mention hit rate beyond the current 7% and potentially unlock more signal.
The news corpus (RSS feeds + Twitter) currently only covers recent data outside our 2019-2023 demand window. As this corpus accumulates over time, Config C (structured + news NLP) will become testable.
The next major step is the Temporal Fusion Transformer — an attention-based neural architecture that handles multi-source time series natively and provides interpretable attention weights. TFT may extract regulation signal more effectively than LightGBM because it can learn temporal lead-lag relationships between regulation events and demand responses.
Comments